

There is a lot of talk from All Flash vendors and vendors of different types of Hyperconverged (combining storage and server with a hypervisor in one package) system vendors also about which type of system is better and provides better data reduction. Unfortunately in most cases their arguments are somewhat simplified from reality.
Some say you need all flash or data reduction doesn’t work, others say you need a hardware card else data reduction doesn’t work, some say you need a traditional SAN. You can get good data reduction from multiple techniques and multiple different systems, so who is right? The truth is that data reduction savings are based more on the type of data being stored, than it is on how you do the data reduction. If you are storing already compressed image data or encrypted database systems, your data reduction savings will be very small if any. If you are storing easily dedupable data like VDI images, or compressible data, like text, then your savings will be good.
Some vendors try to manipulate the numbers to say snapshots are dedupe, or that data provisioned from templates are dedupe, both can be misleading. Taking a snapshot does not reduce data (and is not a backup), however provisioning from template using smart metadata operations does reduce data, but it’s not dedupe. Dedupe only applies when a pattern of new incoming data is recognised and then not needed because the pattern has already been stored in the past. Dedupe works great on some types of application, and not well on others, just like compression works well on some, and not on others.
The worst argument of them all is that you must have all flash in order to get good data reduction or it will impact performance, this is simply not true, unless your vendor doesn’t know how to design their platform. To show that Hybrid software defined systems, which include SSD and HDD, can give good data reduction and there is no problem with performance lets have a look at the results from some real customer environments.
All of the results I’m about to share have been sent into me or my colleagues at Nutanix from environments that are getting these results on standard hybrid systems across many different use cases. Given that I have access to the data about Nutanix this is what I’m using. Other systems may show similar or different results. Based on your particular system the results may vary.
Here is an example a server workload that contains a lot of easily compressible data and therefore shows good data reduction:
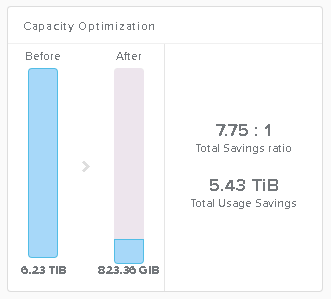
In this case the data was from an Exchange JetStress test. JetStress data is easily compressible and for this reason any system that tests with compression turned on will provide invalid results. So when testing with JetStress you should actually turn off compression. If your storage system can’t turn off compression, then you won’t see real world results (not that JetStress is real world anyway).
This next result is from an Oracle RAC Database. The database contains transactional data, like TPCC would. As a result you get good data reduction. But not as good as if it were just text.

The next example is from a Management Cluster for a VMware environment. It contains vCenter, vCenter Database, VMware Management Tools, Microsoft AD, DNS, and some backup copies of other systems, such as SQL Server and PostgreSQL databases.

A lot of the binary data is already compressed in the above example, so you only get some data reduction savings.
What about real Exchange systems in production environments? Here is an example from a Nutanix customer running an Exchange environment with more than 20K mailboxes. The email data is of all types.

The thing with email data is that one environment can be completely different to another. Here is another example of email data, this time it is from the Enron Email database. Enron is the company that very publicly collapsed after it had a lot of off balance sheet entities and debt. The email database was made public as part of the court proceedings. So it’s a great test case for data reduction technologies.

So in this case we are using compression. Compression is a good choice if data is unlikely to be very common. But you can turn on Dedupe, Compression and other data reduction techniques, such as Erasure Coding all at the same time to achieve the best reduction possible and the platform should work out the best technique to use based on the actual data.
Some types of workload yield extremely good reduction savings from Dedupe, including VDI environments, both full clone and linked clone. Full clone environments yield the best reduction savings from Dedupe, as almost all of the data is duplicated. You can use both DeDupe and compression to get the best possible savings for the data. But here is a couple of different examples from VDI environments.


The above two examples are from two different VDI environments with slightly different workloads. But you can clearly see that the combination of compression and deduplication technology give very impressive savings. But these environments are largely linked clone environments. Not full clone desktops. Here is an example of the data reduction using dedupe in a full clone VDI environment:

This clearly shows that if all of your data is common between the different workloads that you can expect to get extremely good data reduction savings and therefore use very little physical space for those workloads.
So far we have covered a few different types of workloads, but at relatively small scale. But what happens when we scale up to larger environments and more enterprise type workloads?

The above image is from a slightly larger environment that has 10 hosts serving 70 large VM’s doing a lot of large IO. In this case the data reduction is deliver savings of 175TB. But I think we can do better than that. Let’s take the scale up a bit to a slightly larger production environment.

The above example is from a large Nutanix environment with mixed workloads including SQL Server and archive data. In this case the combined data reduction is delivering savings of over 570TB.

The above example is from 2 clusters that each consist of 32 Nutanix nodes. The workloads are general server virtualization with Microsoft applications in one cluster and Linux based applications in the other.

In this above example the cluster consists of 4 all flash Nutanix nodes running on Lenovo HX appliances. The data is a mix of Oracle and SQL Server databases, with a few VDI desktops.

The above image is for a large 26 node hybrid cluster that contains mixed node types and among other applications a 20+TB database.
Final Word
All Flash is not mandatory for data reduction. As you can see from the above you do not need All Flash to get great data reduction savings and acceptable performance. You can get great reduction from hybrid storage environments, and if you choose to go to All Flash you should expect to get the same good data reduction savings. But that decision to go hybrid or All Flash is up to you. Both types of environment can deliver the same reduction savings because it is based on the type of data being stored.
You don’t need special hardware to get great data reduction and performance. All of the above results are from software only and do not require any special hardware. The performance and reduction is dependent on the type of data. Public clouds don’t rely on special hardware, why should your private cloud?
The biggest factor determining data reduction results is the type of data being stored. Yes there are differences in data reduction techniques across various vendors, but the biggest factor that determines data reduction results is the type of data being stored. You need to look through the invalid comparisons using snapshots and calling it dedupe when it’s not. You will get very poor results from data types that don’t reduce well, such as encrypted data, data that is already compressed, images etc. You will get excellent results from data that reduces very well, such as many common images of the same OS or application, data stored in documents, text and databases that has text type data. Because of this it is important that your systems use multiple techniques of data reduction so that you can use the best reduction based on the actual type of data.
Some benchmark tests will provide invalid results if compression is enabled. If your system doesn’t allow you to turn off compression and dedupe you may get invalid results during some types of benchmark testing, such as with Exchange JetStress. This means you can’t use these results to determine how production environments might behave.
Snapshots and clones are not included in the above results! Snapshots and clones, which use metadata operations only, do not increase data and therefore are not included in data reduction results and reports on the Nutanix platform. They also do not increase storage usage, as they don’t create any net new data until new writes are received. Therefore you can take as many clones and snapshots as you like and it doesn’t impact your useable storage. Other vendors have chosen to report this as part of their data reduction savings, however Nutanix only reports savings from actual compression or data deduplication resulting from real pattern recognition.
To sum all of this up. Your data reduction will be based on the type of data that is stored more than anything else. Due to this your milage may vary. Use real world data and real world workloads in any pilots so you can see what real data reduction might be for your real workloads. Big thanks to all of the customers that submitted images with their permission to use them anonymously in this article.
—
This post first appeared on the Long White Virtual Clouds blog at longwhiteclouds.com. By Michael Webster +. Copyright © 2012 – 2016 – IT Solutions 2000 Ltd and Michael Webster +. All rights reserved. Not to be reproduced for commercial purposes without written permission.
== Disclaimer – Pure Storage employee ==
Michael,
I’d like to elaborate on some of the points in this post. Some i vehemently agree with and others… well let’s say I have a differing opinion.
When it comes to data reduction results, both the data type and the implementation of the data reduction technologies will determine the results. For example, look at a complex data set to reduce like Oracle. By in large, these databases are more conducive to data reduction via compression algorithms than deduplication.
Inline compression processes tend to produce modest results with Oracle (let’s say 1.5:1 to 2:1 on average). This is due in large part to the storage platform prioritizing serving host side (or front end) I/O over achieving maximum data reduction. Platforms with background compression processes tend to produce greater data reduction results (let’s say 3:1 to 4:1), although the capacity savings are achieved sometime in the future. The Coup De Grâce are the platforms that implement both inline and background.
With data deduplication, inline or post process tends to be a moot point. Granularity of the implementation will correlate to the reducibility of data. Fixed block implementations are challenged (and often unable) to find commonalities due to the unique block header and tailcheck section of each data block in the database. Variable length dedupe with 512B granularity provides a ‘sliding window to operate within and thus can find a 7.5KB dedupe match in the default Oracle data block size of 8KB.
With all considerations to data compression and deduplication, data reduction will be reduced if the contents of the database are encrypted. The loss of reduction often closely correlates to the complexity of the encryption.
Bottom line: data type and the implementation of data reduction technologies mater equally in terms of results. I would position that testing dedupe friendly workloads like VDI will produce the most similar results between dissimilar storage platforms, whereas a varied testbed will produce varied results; allowing a customer to best determine the capabilities of the data reduction engine for broad adoption.
All of this is meaningless unless we go beyond the technical vacuum and consider the impact of implementation on performance.
I believe the poignant point the AFA vendors have put forth is affordability with high performance. Modern AFA’s tend to provide robust storage efficiencies (data reduction and dual-fault, parity based data protection) and sub-millisecond, high performance I/O.
While flash is fast, one needs to understand that architectures matter. For example, readers can refer to a recent Storage Field Day 9 presentation, where an all-flash HCI configuration produced sub-millisecond latency results with an OLTP workload. These high performance results were obtained on a capacity inefficient mirroring and no data reduction configuration. In other words, strong performance was achieved from a costly configuration (much more expensive than an AFA). Test results declined to around 6.5ms (aka high end hybrid class) with a moderately more cost effective configuration (mirroring with data reduction) and no results were shared from testing with a cost efficient architecture (erasure encoding and data reduction).
I share these points not as a means to go negative but to reinforce clarity of message. Modern AFA platforms promote affordability and high performance. This combination allows one to run their most demanding workloads alongside those that are cost sensitive.
I’d suggest in order to demonstrate data reduction results with a hybrid architecture that are similar to what is possible from a modern AFA, then you need to share test results that go beyond the modest I/O profiles (bandwidth and IOPs) shared in this post.
I commend you for having the courage to ‘lift the komono’ if you will, but based on the results shared in this post, I don’t think you have demonstrated that data reduction can be enabled for every or even most workloads that reside on a platform with a hybrid storage subsytem.
– Cheers,
v
(apologies in advance for any typos)
Thanks for the comments. No doubting that all flash provides the best and most consistent performance over the range of applications and data types. This is why HCI vendors including Nutanix provide All Flash configurations. Still for Nutanix data reduction and performance from all flash go hand in hand. However these are examples from real customer environments and not tests that we have done at Nutanix. As more customers submit data I plan to update this article. Including with All Flash results. Data reduction on hybrid platforms provides more effective flash before you run into the impact of HDD on performance. The main point I’m trying to convey is that All Flash is not mandatory for good data reduction. But with data reduction techniques where they are today All Flash is certainly an attractive proposition for a lot of workloads. Regardless of which vendor a customer decides fits their requirements best.
I also agree with you that a comprehensive data reduction implementation that includes both inline and post process activities provides the best possible results. But based on the data I’ve got I still see the type of data being more of a factor in determining end results. The exception is smart clone / snap / copy metadata techniques, which give the same result regardless of data type due to no underlying data changing.
Great article. I think the strongest point here is that focus show be on the type of Data AND type of implemented reductions techniques used rather than on the media (HDD, SSD, etc.) although I fell that when facing customers, that turns out to be an exercise in itself since it requires deeper assessment on the environment to build a proper business case…
I need to correct a mistake I made in my earlier comment re: the SFD9 test results with an AFA configuration. The sub-millisecond results were obtained on a configuration which was capacity inefficient (single mirror without data reduction0. The test results declined to around 5.5ms with a moderately cost effective configuration (single mirror with data reduction) and 6.5ms were achieved from a more cost efficient architecture (RAID 5 erasure encoding with data reduction).
The point I was trying to convey was the trade off in performance and cost based on implementing capacity efficiency technologies. The SFD9 presentation did not include results obtained with a cost optimized (RAID 6 erasure encoding with data reduction enabled) configuration.
My apologies for misrepresenting the results in my prior comments.
[…] Real World Data Reduction from Hybrid SSD + HDD Storage […]
[…] Оригинальный пост на английском тут: http://longwhiteclouds.com/2016/05/23/real-world-data-reduction-from-hybrid-ssd-hdd-storage […]
[…] that exist with more traditional storage systems based on spinning disks. As I demonstrated in Real World Data Reduction from Hybrid SSD + HDD Storage you don’t need flash to get data reduction, but flash storage with data reduction […]
[…] Real World Data Reduction from Hybrid SSD + HDD Storage […]