


It was about this time in 2013 that Michael Corey, Jeff Szastak and I started writing Virtualizing SQL Server with VMware: Doing IT Right (VMware Press) 2014. Microsoft SQL Server was the single most virtualized business critical app in the world then, and it is still the case today. Our book is still as relevant today as it was when we published it and the recommendations we documented still hold true. In spite of it being the most popular critical app to virtualize there are still a lot of cases where some simple best practices are not followed. Best practices that could greatly improve performance. Not all of the best practices apply to all database types at all times, so some care is required. One thing we’ve learned with experience is that the only similarity in customers’ database environments is that they are all different. So this article will focus on the top 5 things you can do to improve performance for many different types of databases and give some examples from performance testing that my team and I have done.
SQL Server Memory Management – Max Server Memory, Reservations, Lock Pages, PageFile
SQL Server, like any RDBMS is really a big cache for data at the end of your storage, regardless of what storage is under the covers. Allocating the right amount of memory to the SQL Server Instance, and ensuring the Operating System has enough memory so it doesn’t cause swapping, are our primary goals. Then we need to look at protecting the SQL Buffer Cache from paging and protecting the VM memory. Paging of the database buffer cache can cause sever performance problems for a busy database server.
Max memory should be changed from the default of 2PB to a value that allows the OS some breathing room. On small SQL Server VM’s with only 16GB or 32GB RAM setting Max Memory to Allocated Memory – 4GB is a good place to start. For larger VM’s the OS may need 16GB or 32GB, and this can be impacted by the number of agents and other tools you have running in the OS. I have seen recommendations that you should leave 10% available for the OS, however this becomes problematic if your VM has a lot of RAM, say 512GB to 2TB.
Reserve the memory assigned to the SQL VM. This guarantees the service levels to the SQL Database, ensures that at least from a memory standpoint it will get the best performance possible, and it will mean the hypervisor page file will not take up any valuable storage. For SQL server VM’s > 16GB memory, and where lock pages are used this is even more critical as hypervisor ballooning is not effective.
Enable the local security policy “lock pages in memory” for the SQL Database service account and set trace flag -T834. This will ensure that the SQL Server instance uses huge pages on the operating system and it protects the database from any OS swapping, as huge pages can’t be swapped. This also reduces the work the OS needs to do with regard to memory management. Huge pages on x86 are 2MB in size, vs the standard 4KB page size that is used by default. Using this setting also prevents ballooning from impacting the SQL Server Instance and is another reason to reserve the memory.
I recommend that you allocate a pagefile big enough for a small kernel dump at minimum, and up to 16GB to 32GB as maximum. If you design your SQL Server VM properly you will not have any OS paging, therefore you shouldn’t need a large pagefile. If you are designing a template that will be used for multiple different sized SQL VM’s then you could consider setting the pagefile to a standard size of 16GB and leaving it at that. The less variation required the better. By reserving the VM memory, locking pages in memory and using -T834 the buffer cache of the DB can’t be paged anyway. These settings will ensure the best possible service level and performance for your database at least in memory.
Split User DB Datafiles and TempDB Across Drives and Controllers
This applies especially to high performance databases. SQL Server can issue a lot of outstanding IO operations and this can cause the queue of a particular drive to become full and prevent the IO’s from being released to the underlying storage for processing. To help alleviate this for large high performance databases you should create the databases with more than one data file (recommended 1 per vCPU allocated to the DB), and allocate each datafile on a different drive. If you have many smaller and less high performance databases you can simply split the database data files across more drives or mount points if you determine a single drive does not provide sufficient performance.
For TempDB the recommendation is 1 datafile per vCPU up to 8 initially and then grow 4 at a time from there as needed. The process of allocating datafiles to TempDB has been automated in SQL Server 2016 so it will choose the correct initial number based on the number of vCPU’s allocated. The reason for doing this is to prevent GAM and SGAM contention.
Each virtual drive and each virtual controller has a queue depth limit, so splitting the datafiles across controllers also helps to eliminate bottlenecks. In a VMware environment you can use up to 4 virtual SCSI controllers, such as PVSCSI and it would be recommended to split the data files across them. You can also tune each controller queue depth by changing registry settings, but be aware of the potential impact on your back end storage. Having really large individual drives / virtual disks might give you extra capacity but it gives you no more performance as the queue depth per device is always limited. This is also the case in cloud environments such as Azure and aligns with Microsoft SQL CAT recommendations.
The image below shows one such design that may be appropriate for splitting data files. This example uses mount points, but you could also use drive letters.
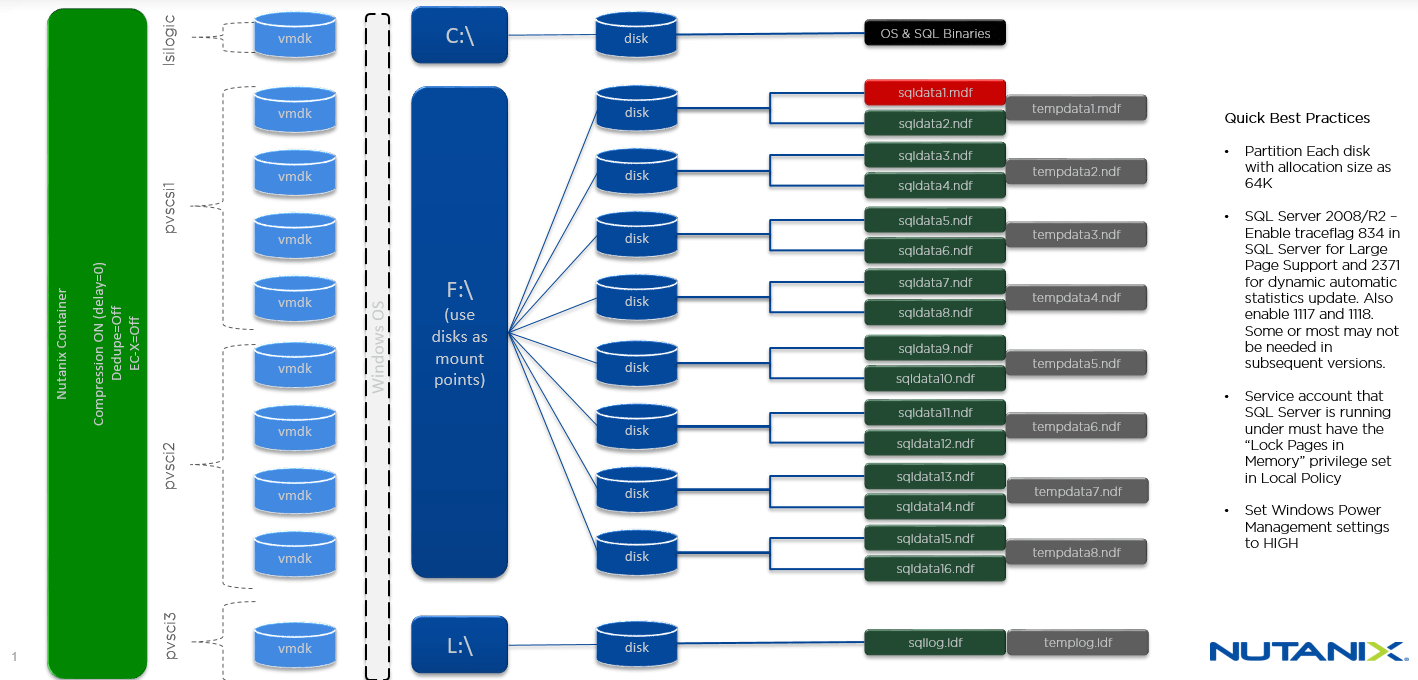
Thanks to Kasim Hansia and Nutanix for the above image.
CPU Sizing, NUMA and MaxDOP
When it comes to CPU sizing for your database VM’s the best size is one that fits within a NUMA boundary. So for a two socket platform this would be a size that fits within a single socket or is easily divisible by the number of cores in a single socket. If you have very large physical servers currently with many databases on them, chopping them up into smaller size VM’s that fit within a NUMA node will help improve performance. The best size of a VM on a system with 8 cores per socket would be 2, 4, or 8 vCPU as an example. In terms of CPU overcommitment a 1:1 vCPU to pCPU core ratio is recommended to start with unless you have a good knowledge of actual system performance, at least for critical production systems, for dev/test a higher ration can be used to start. You can modify increase the ratio as you monitor actual system performance. Production systems general run between 2:1 and 4:1 realistically assuming not all database instances and VM’s running on the host or cluster need the same resources at exactly the same time. You need to design for peak workloads demands and then the averages will take care of themselves.
For very large databases this may not be possible and in that case it is ok to have a VM that spans NUMA nodes as Windows and SQL Server are NUMA aware and will use the processors available to them assuming the correct license, however the scaling of processors across NUMA boundaries in a single VM doesn’t provide linear performance, whereas splitting multiple smaller databases across multiple smaller VM’s that do fit within NUMA boundaries can provide better performance than would otherwise be available on a single physical OS or VM. When it comes to memory and NUMA, more is better for databases and as memory is so much faster than disk or SSD or even NVMe, the penalty for having memory in different NUMA nodes when virtual NUMA is available is not a concern.
With regards to the SQL Server setting Maximum Degree of Parallelism that controls the number of threads or processors that a single query can consume, you need to be careful with modifying it. For OLTP transactional type databases you can get significant performance gains overall when large numbers of users are concurrently accessing the system if MaxDOP is set to a small number or 1, however it is a global setting on the SQL Server instance in versions before 2016 and therefore will impact all databases on an instance. A good rule of thumb may be to set it to an the size of a NUMA node, or some number of processors you are happy to be consumed by a single query. In SQL Server 2016 you can set it per database, so it can be more finely tuned to the individual database workloads. Leaving it at the default of 0 i.e. unlimited can also have negative performance impacts especially when many users access a database as a single query could consume all resources and negatively impact other users.
Networking, Live Migration, Jumbo Frames
When it comes to networking you need to consider more than just the user access to the database, you need to consider management workloads including live migration for maintenance and load balancing, backup, monitoring and out of band management. With very large SQL Server VM’s with 512GB and above the live migration network may have some hefty requirements. Especially with very active SQL Server VM’s. I have seen the live migration networks struggle with evacuating a host for maintenance if they were not designed and implemented correctly. If you have hosts with multiple TB of RAM and enough VM’s to occupy that RAM you should consider multiple 10G networks for live migration traffic. Using LACP network configurations can indeed help, as can using Jumbo Frames. As you start adopting 40GbE, 50GbE and above NIC’s the use of Jumbo Frames to increase performance and lower CPU utilization becomes ever more important. You can achieve up to 10% to 15% additional performance by using Jumbo Frames for live migration traffic depending on CPU type and bandwidth of you NIC. But take care as it does need to be implemented properly. It is fortunate that many enterprise class switches now come with Jumbo Frames enabled by default, but you will still need to enable it in your hypervisor and on the life migration virtual NIC. If you are using Jumbo Frames why not enable SQL Server to use a packet size of 8192 bytes instead of the standard 4096 (same size as a database page although there is no direct relationship), 8192 bytes and it fits nicely into the 8972 byte TCP packet (9000 bytes with overhead included) on the wire. Take into consideration the network impacts of any software defined storage solution especially as adopting modern all flash systems because your network may be too slow for flash.
Maintaining an Accurate and Objective Performance Baseline
Maintaining an accurate and objective performance baseline of your databases is the only real way to measure when things are going wrong or when performance is not acceptable. Before, during and after virtualization you should be updating your baslines whenever major configuration changes are made. This prevents the ‘feeling’ that it’s slow, without defining what slow it, or without being able to quantify the feeling. If you can accurately test acceptable performance and repeat that test then you can be sure your system is behaving as expected throughout its useful life. This is not as easy as it sounds, and due to the many hundreds or thousands of databases that most customers have, a risk based approach is recommended. For the most important or highest risk systems it’s worthwhile making the investment into proper baselines and monitoring, for the great unwashed this might not be practical. There are many tools that can help, and they start from industry standard benchmarks and system monitoring tools to more elaborate enterprise test suites. We cover a number of different options in our book, but a simple option might be to use HammerDB, Record and Replay, and/or SCOM/PerfMon. Without a baseline you have no objective way to measure success.
Performance Results With and Without Best Practices
When you’ve been successfully virtualizing SQL Server for years and you know the best practices it is pretty hard to go back and create a database VM with next, next finish and ignore all that you have learned. But that is just what we had to do in order to measure the difference between the default configuration and applying the best practices. In this case we used a VM with 8 vCPU, 32GB RAM and HammerDB. The only difference between the two tests was the configuration of SQL Server and the operating system. The same number of users in HammerDB are used for each test.
Default configuration without best practices applied:

Configuration after best practices have been applied:

Thanks to Bas Raayman and Bruno Sousa for the two images above.
In this example the difference in performance is 12x between the default configuration and the optimized configuration. The benefits grow as you start to scale out the number of VM’s and number of servers, which is what the next image shows.
Here we have a number of database VM’s being scaled our across a number of servers, in this case using Nutanix systems. The performance growth is linear, as you add more VM’s and more Nutanix nodes you get the same performance per node, and linearly scalability of the overall performance in terms of transactions per minute.
#TBT A blast from the past (2014) Scaling 1M MS SQL transactions per #Nutanix node.https://t.co/CDwiVQKMbQ pic.twitter.com/eViiA3b10m
— Gary Little (@garyjlittle) January 26, 2017
Final Word
We have covered a few best practices that can help improve performance and ensure success of any virtualization project. There is significantly more covered in Virtualizing SQL Server With VMware: Doing IT Right (VMware Press 2014). I also had a hand in crafting the Nutanix best practices for SQL Server, which is freely available. Nutanix has published many best practice guides for many applications and a lot of them are applicable regardless of what system you are running. Hopefully applying some of these simple best practices helps improve the performance of your virtualized SQL Server environments. I’d love to hear any feedback or comments you might have.
This post first appeared on the Long White Virtual Clouds blog at longwhiteclouds.com. By Michael Webster +. Copyright © 2012 – 2016 – IT Solutions 2000 Ltd and Michael Webster +. All rights reserved. Not to be reproduced for commercial purposes without written permission.
[…] via Best Practices for Running SQL Server Virtualized — Long White Virtual Clouds […]
Great stuff as always! Thanks!
Hi Michael, great article!!. I have a questions. We have a VM monster SQL Machine on a nutanix block with 28 physical cores (2 x 14 and Hyperthreading enable) model 8035-g4, And since we installed Nutanix, I have assigned 2 physical processors with 12 cores each processor
I have been doubt, which configuration is better, ratio 1:1 VCPU to pCPU i mean i must have assign 12 physical processor with 1 core each processor to obtain a better performance? or my configuratoin is ok?
regards,
Hi Carlos, what you have assigned is perfectly acceptable. For that size VM the configurations would have the same result as Virtual NUMA will tell the VM the physical topology.
In your data file split image above…..you have the mount points listed as VMDK files……would these best practices need to be altered in any way if the mount points were actually iSCSI LUNS delivered via Nutanix ABS vs. the VMDK files?
Hi Rurik, it would work the same if using ISCSI, except in that case they wouldn\’t be VMDK\’s but ISCSI LUNs.
Hi Michael,
In the disk design image, with the 8 VMDKs being set as Mount Points on F:, where does F: itself live? I’m assuming it would be another VMDK that’s not on the diagram (unless I’m missing something obvious). Thanks.
Hi Jesse, F: Drive is just another VMDK, usually very small, say 10GB, and the mount points just live on that.
Hi Michael,
I thought it might’ve been something like that, thanks for the confirmation. I’m assuming it doesn’t matter which controller it’s on since there’s no real I/O going through it? (like, it could be on the first controller that has the OS VMDK)
Correct, doesn't matter which controller it goes to.
vcdxnz001 – Can you please advise on the creating Virtual Disks ?
For backup & Logs disks – Should they be Independent (persistant) or dependent disks ??
Issues with Independent disks – Can’t take snapshot & backup
Dependent disks – If I take snapshots then due to Delta file & needs consolidation.
Advise with source from Vmware or MS will be helpful.
Hello, excellent article. I have a doubt. How can I do to estimate the working set of a SQL Server?
Assume 100% unless you have data saying otherwise. This is because of regular maintenance jobs that cover the whole DB. Another way is calculate 4 x the incremental or differential backup for a month. But usually you want SQL on all flash anyway. So no need to calculate working set then.
This is such a great article. Any recommendations on how to properly downsize a SQL VM if it is overprovisioned? We have 12 vCPUs currently, but that’s spanning NUMA of the physical hosts – they’re dual socket 8 core per. I wonder if we’d be underprovisioned at 8 vCPUs. Any way to tell if there are performance hits from spanning NUMA on the physical host?
If the DB needs the resources there should be no penalty. SQL is NUMA aware. If the DB only needs 8 VCPU, that would be a better size.