

One of my fellow vExperts, Prasenjit Sarkar, has recently published a blog article titled Virtualizing BCA – What about application IO characteristics. I recommend that you take a look at this as it gives a good overview of a lot of the considerations around storage for Business Critical Applications. There are a few things I feel are also important over and above what is mentioned in the article and these may have a significant impact on your architecture design and application performance. Here I’ll cover some things you must consider to provide a solid storage design to support your most critical systems.
I will cover off each of the topics in Prasenjit’s article in the order he wrote them to make it easier to follow. Prasenjit has done some great work and my objective for this article is to add to that.
Randomness of IO
The randomness of IO is a very important consideration in storage design. Most virtualization environments will generate a completely random IO pattern even with sequential IO from individual VM’s. This is because the underlying VMFS datastores are shared between multiple VM’s in most cases. With business critical apps you will have cases where VM’s should or will still share some common VMFS datastores. The only way to have any chance of sequential IO is to have dedicated VMFS datastore for a single VMDK or to use RDM’s for your guests. RDM’s will limit your flexibility and there is not performance difference between RDM and VMFS, so VMFS should be the preferred option in most cases. As soon as you add a second VMDK to the VMFS datastore you increase the chances that your IO pattern will be random and not sequential. My advice would be to plan your storage subsystems with a 100% random IO pattern in mind and design the storage layout of your VM’s to share VMFS datastores intelligently when possible, and have necessary separation for performance where required. I would suggest you only use RDM’s if you need a particularly large single volume (>2TB in vSphere 5), or you want to be able to swing between physical and virtual.
Read/Write Bias
Be very careful around your read and write bias calculations and percentages. Just because an application generates a read biased workload doesn’t mean the underlying storage system will see a read biased IO pattern. The reason for this is Application cache and OS filesystem cache is likely to mask a lot of read IO if you have sized your guests correctly. This will mean your IO patterns may be very write biased. You will need to make sure you have sufficient write cache so you don’t get into a position of a force flush and a subsequent instance of the cache going write through which will significantly degrade performance. You must have sufficient physical devices in the array to handle the cache flushes easily. Be very careful when using SATA disks on an array without automated storage tiering. Overloading a SATA LUN can cause forced flush and significant periods of array cache write through, to the point where the storage processors may appear to freeze and you may find LUNs being trespassed on active/passive arrays, or just lots of path flip flops on active/active arrays.
There is a direct trade off between Read IO’s hitting your array and memory assigned to your guests used for application and filesystem IO cache. So you should assign sufficient memory to your guests to balance the IO workloads. You should at all times attempt to avoid OS swapping. Swapping will have an immediate and direct impact on your storage and your application performance. You will want to use reservations on your guests to limit the likelihood of swapping at the vSphere host level, and also at the guest OS level. It may be acceptable during a host outage to have some swapping and slightly degraded performance. You should very carefully consider the business requirements and the impacts of sacrificing guest level caches during host failure events, your reservation levels on your guests, your memory assignments, to get the best balance of performance, risk and cost, even when things go wrong.
Fixing a read IO problem is in a lot of ways harder than fixing a write IO problem as with reads where it goes to the physical storage subsystem it must spin the disks to read the data out in most cases. This is due to the very high percentage of read cache misses on the array due to the randomness of the IO patterns. In most cases it’s not worth in my opinion having any cache assigned to read at the array level, and instead having it all assigned to write. Write peaks and micro bursts can mostly be handled with the write cache, and then be trickled down to the physical disks.
One way of sorting read IO without assigning huge amounts of memory to your hosts is by using local shared host cache and acceleration technology such as Fusion IO cards. Fusion IO cards are oem’d by all the big name brand server vendors. So check with your server vendor and your Fusion IO team for more information. Deploying local host caching technologies like Fusion IO can allow you to consolidate more workloads on your servers with less assigned memory. Instead of assigning lots of memory to your guests for IO cache you essentially offload this to the Fusion IO card, which is much more cost effective per GB, but not as high performance as RAM. It will be a balancing act and you will need to test it. I will be testing Fusion IO’s technology with Oracle RAC systems running on SLES 11 SP1 over the next couple of weeks and will blog about it. Fusion IO cards when used as cache will be write through and are only used as cache for reads. This is important for data integrity. The system will also keep operating perfectly fine if the card fails, although at less performance. So consider card failure in your design and plans and how you’ll handle that if you choose to go down this path. If the card fails all the IO’s that the card would have serviced will immediately start going directly to the storage.
Important Note: The write biased nature of workloads is incredibly important to understand and consider to achieve the optimal storage design. I can’t emphasize this enough. This also applies to VDI workloads (not just server workloads), which I also class as business critical applications, as VDI is also generally very write biased.
Spindle Count, IOPS and Capacity Calculations
My general philosophy when it comes to sizing storage when virtualizing business critical applications is to size for performance first, and generally capacity will take care of itself. If you just look at capacity you will find that most of that capacity is simply unusable from a performance perspective. Find the storage solution that best balances capacity and IOPS and that meets your latency requirements. Wikipedia has a great page on IOPS, it’s definitely worth checking this out also.
In some cases you may find adding in smart local host cache or acceleration technology, or using SSD in the storage arrays can actually save you a lot of money. The reason for this is that you can deploy much fewer devices, that consume much less power and cooling, are easier to manage, to meet your performance requirements. Individually compared to their spinning rust counterparts the SSD’s may cost significantly more, but because you need so few of them to meet your performance they can be very cost effective. In the case study that Prasenjit presented it may have been possible to meet the performance requirement with a single SSD, but as that wouldn’t provide the capacity or redundancy you’d need a few more. The lifespan of enterprise SSD’s is sufficient these days so it is no issue, and the cost is coming down all the time. SSD’s are becoming a very common technology in enterprise storage environments. To get the capacity requirements for the case study or 1TB you could have deployed 4 SSD’s in a RAID 5 – 3+1 configuration (very common with SSD’s).
From a pure cost perspective SSD could be between 7:1 and 10:1 when compared to SAS or FC disks of similar size. However in my example above this would still have produced a significantly cheaper solution. For the cost of only 28 – 40 spinning rust devices you would have got significantly more performance than the otherwise required 50 disks to meet the performance requirements from Prasenjit’s case study. You would also significantly exceed the latency requirements using SSD’s when compared to SAS or FC.
IO Request Size
Just because an application produces an 8K IO request doesn’t mean the storage array sees an 8K IO request. This is because the Guest OS will most likely try to order and combine the IO’s to achieve better performance. With Linux the best IO scheduler to choose in a virtualized environment is NOOP or No Opperation. This will simply order and group the IOs without delaying some IOs like other schedulers do to attempt to get better performance. The simplest scheduler is the best due to the multiple layers of the storage IO stack and the multiple layers of virtualization that are commonly in the environment. The other IO schedulers were designed for a time when direct attached disks were common and even when single disks were used.
Important Note: The vSphere Hypervisor doesn’t try and order or group IO’s. It will just spit them out to the HBA driver / storage as they are received, and in the size they were received from the Guest OS’s. Also very important to note is that vSphere does not itself do any caching. This is to ensure data integrity.
Other Things to Consider
- Things will go wrong. You can’t plan your performance around storage subsystem components working all the time. Plan for performance during failure events such as lost disks and disk rebuild, lost paths, etc. Remember the performance penalty of RAID 5 when a disk in the RAID group has failed and also the additional risk of having a multi-disk failure during rebuild from your hot spare. SSD’s will rebulid significantly faster than SAS/FC disks. Jury is still out in terms of failure rates of SSD when compared to traditional spinning rust, but due to the fact they have no moving parts it should give SSD’s a big advantage in that area. Check out Tom’s Hardware article on SSD Failure Rates.
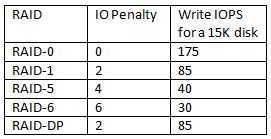
- Every IO operation has a RAID penalty associated with it and you don’t ever get the full cumulative performance from all the disks, assuming you’re not running RAID Zero! Here is a good post on IOPS RAID Penalty and Workload Characterization by Sudharsan and Getting the Hang of IOPS v1.3 in the Symantec Community (a must read). Duncan Epping has also done a great article on IOPS, it is a must read and has some excellent comments. The below image is directly linked from Duncan’s article. The image are for the RAID penalty associated with write IOPS.

Read IOPS also have a penalty in same cases. Especially in the case of failure. Make sure to take the Read penalty in the case of failure into account. Also note with RAID 1 and RAID 10 the read performance is 200% as data is read off two disks at the same time. Also take account of the performance impact during rebuild operations and the risk of second disk failure during rebulid. When calculating maximum read performance during normal operations exclude the parity disk. So in a RAID 5 – 7+1 configuration your read IO performance will be the combined IOPS of the 7 disks. - When using spinning rust RAID 10 in some cases can be more cost effective than RAID 5 due to being able to meet the same performance requirement with less disks and continue to meet the performance requirement during single disk failures. It’s also of course more resilient as it can in theory survive multiple disk failures provided the failure doesn’t impact two disks from the same mirrored pair. RAID-DP offers a good balance of performance and capacity.
- When using a shared VMFS datastore, which I have with many successful business critical applications projects, consider IO scheduler fairness and how the IO scheduler with handle the VM’s combined IO load. Consider combining low IO consumers with higher IO consumers to get a better balance between capacity and performance. Consider storage tiering.
- Fully Automated Storage Tiering can have a dramatic performance and cost benefit to your environment and will negate much of the calculations you’ve done regarding the IO performance! So take the time to talk with your storage vendor on how your calculations and storage design for your business critical applications will be impacted.
- Use Storage IO Control to smooth out any rough patches with IO latency. You shouldn’t be experiencing bad IO latency in the first place, but in the cases where things go wrong, or when using auto tiering SIOC can help. If you’re array isn’t dedicated to the business critical apps or virtualization infrastructure then you are going to have less predictable performance and also SIOC may not be as effective. Remember that SIOC when it kicks in is trading off throughput for lower latency. It will also help you prevent noisy low priority VM’s from impacting the performance of your high priority VM’s. This means you will be more likely to be able to virtualize business critical apps along side less critical apps on the same shared storage without risking your SLA’s. Please make sure you test this functionality during your project and that you understand the impact it will have on your environment.
- Consider spreading IO loads across multiple virtual disks, multiple vSCSI controllers and multiple datastores where required. Consider the PVSCSI adapter if the OS supports it and the perf benefit of this over the other options.
- Very carefully consider queue depths and storage IO queues in general, queues are everywhere. You may want to adjust the queue depths either up or down depending on your architecture and applications and workload requirements and storage array capabilities. Be careful not to exceed the queue depth on your array. A queue full situation is not something you want to experience.
- Consider the IO load of non-application IO loads in your calculations, such as boot storms, virus updates and scans, backups, replication, storage migrations and re-organizations, you want to avoid your array hitting the red line and impacting application performance and availability. Be aware that IO load at production varies significantly from IO load placed on the DR systems in a replicated storage environment. This means if you’re using auto tiering the auto tiering at DR will be wrong and when you need to test, or to fail over, it will take a period of time to adjust and get things correct. This aspect should be planned into your design. Some of the storage vendors have solutions to this problem, and the correct solution will depend on how the actual site resilience is achieved.
- When using SSD’s in a shared storage array the configuration of the back end storage is very important in order to maximize the usable performance. It is possible to overload internal interconnects in the array and almost have a denial of service type condition between different classes of storage as the SSD traffic can be so much higher and faster than SAS/FC and SATA/NL SAS. You also don’t want to be overloading your front end or back end ports in the arrays. Your storage vendor and storage architects are best placed to provide you good advice on this aspect.
Final Word
Three maxims of cloud apply to this just as with most things. Hardware fails, people make mistakes and software has bugs. You need to plan and design for all of this. You owe it to your applications to take a very methodical and carefully thought out approach to storage design to ensure their performance and availability requirements are met. The time taken in the storage design is justified due to the critical nature and impact of these business critical systems. This type of design effort should be no less than you would have applied had this system been deployed to a native OS/Hardware combination. The benefits you will gain by virtualizing and consolidating multiple workloads with thought and care will far outweigh the cost of doing the design properly the first time, rather than trying to do it over if you run into a major issue.
If you are going to have databases or systems with large disk footprints (and have multiple per host) you may need to modify the ESXi VMFS Heap Size by changing the advanced setting VMFS3.MaxHeapSizeMB. Review KB 1004424 and Jason Boche’s article Monster VMs & ESX(i) Heap Size: Trouble In Storage Paradise.
If the business critical application you are virtualizing is Oracle then check out my other articles on virtualizing Oracle. Deploying Enterprise Oracle Databases on vSphere is especially relevant to deploying business critical Oracle databases and the associated vSphere design considerations, including some nice design diagrams.
For additional information on virtualizing Oracle visit my Oracle Page.
—
This post first appeared on the Long White Virtual Clouds blog at longwhiteclouds.com, by Michael Webster +. Copyright © 2012 – IT Solutions 2000 Ltd and Michael Webster +. All rights reserved. Not to be reproduced for commercial purposes without written permission.
[…] and VCDX #66, Michael Webster has written the other considerations in terms of Storage when you Virtualize your Business Critical Applications. Have a look at the article, he has shown the whole gamut of […]
Michael,
This is really nice. I wanted to make it short and crisp. But you have the whole gamut here. I like the end-to-end picture. I am writing on the RAID level case study, what to choose why to choose and when. Also backup and recovery, MTTR, MTBF determination and replication of these BCA workloads.
So, my intention is to cut it in multiple. Please have a look at those when it is published and let others know (the way you just did) how we can leverage those factors.
Thanks again.
Rg,
Prasenjit S
Hi Prasenjit, You've just raised another great point. Replication overheads and the performance impacts of that on storage and applications. Also the size of each LUN and how that maps to recovery, replication, failure risks. Change rate impacts on replicated storage. These are also things that needs to be considered. MTTR and MTBF also come into it too. Google research on disk MTBF is very interesting, as it bares almost no relationship to annualized failure rate or the vendors published figures. I'll definitely be taking a look at your other storage articles when they are published and letting everyone know about them.
Fantastic article!! It just hits so many hot spots within the storage design piece.
As more and more workloads are offloaded to public clouds it would be interesting to see how the many providers manage their storage infrastructure. It's comparatively easy to manage servers which are under your control in a corporate environment, however when random customers are spinning up servers on shared infrastructure it's a lot harder to control and cater for.
I think it would be worth mentioning about the data path designs which one might take while designing the storage environment for the virtual infrastructure. Would appreciate an inclusion of vSphere NMP against some of the array based multipath solutions available. In real customer scenarios, I have seen them investing on multiple FC ports/iSCSI ports on the host end, fabric and array level, however a lot of them are unsure of how and what is best for them when it comes to selecting the multipath policies for there storage luns.
for eg. how Round Robin is the most chosen one, however it still uses only one path at a time and moves on to the next one, once the path has reached the permissible limit of SCSI cmds or IOps.
All in a all, a great article!!
Regards
Sunny
[…] Before we get started I’d like to say this article isn’t going to cover performance of large volumes. But rather the argument for supporting larger than 2TB individual virtual disks and large volumes. There are many considerations around performance, and I will cover some of the implications when you start to scale up volume size, but for particular performance design considerations I’d like to recommend you read my article titled Storage Sizing Considerations when Virtualizing Business Critical Applications. […]
[…] and produced very low latency. The IO Size and Latency being important factors as I outlined in Storage Sizing Considerations when Virtualizing Business Critical Applications. See What’s New in VMware vSphere 5.1 – Platform and What’s New in VMware […]
[…] wrote a previous article titled Storage Sizing Considerations when Virtualizing Business Critical Applications that covers some of these topics in more detail. I would highly recommend you review this as […]